“What Have Hazard Logs Ever Done for Us? Well, there’s the aqueduct…” Monty Python’s Flying Circus may not be an obvious connection to hazard management, but it works! Hazard Logs – or Hazard Tracking Systems (HTS), which is a better term – are underappreciated but vital tools.
In this webinar on hazard logs, one of the topics that I will be covering is what a ‘full-function’ HTS can do. By that, I mean a purpose-built database, rather than just a spreadsheet. So here is a taster of the benefits, derived from my 25+ years of experience on system safety programs, large and small.
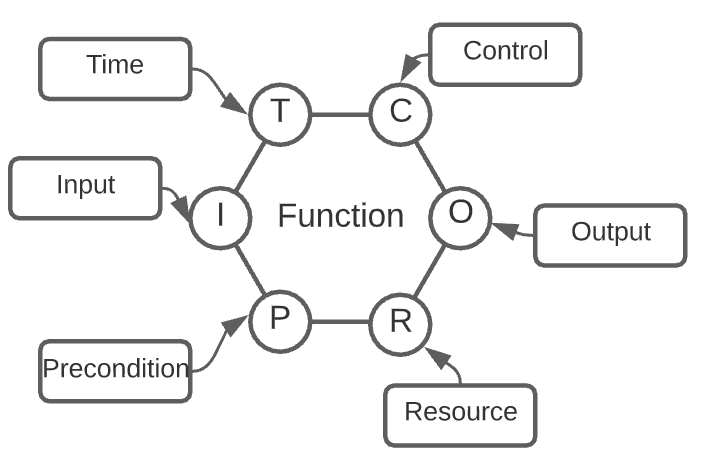
Key Elements of a Hazard Log
An HTS pulls together key safety data about:
Accidents: ‘An unintended event, or sequence of events, that causes harm’;
Accident Sequences: ‘The progression of events that results in an accident’;
Causes: that may lead to a hazard;
Controls (or mitigations): ‘A measure that, when implemented, reduces risk.’; and, of course
Hazards: ‘A physical situation or state of a system, often following from some initiating event, that may lead to an accident’.
Accident Sequence
Understanding how causes lead to hazards, and hazards lead to consequences, which may include (harmful) accidents, is fundamental to understanding accident sequences. This in turn helps us to understand the mechanisms that lead to harm – and defeat them.
Managing Many-to-Many Connections
A Hazard Log doesn’t just store data elements, it links those data together meaningfully to make information. A relational database does this by allowing us to make many-to-many connections between different classes of data.
Hazard Log Connections
This allows us to do a lot of useful things. We’ve already mentioned understanding the mechanisms behind accident sequences. This allows us to design or select effective controls to interrupt the accident sequences and prevent harm.
Discovering Pathways to Harm
Understanding these links also enables us to see connections, for example between causes and accidents, which we had not seen before. This is important, as many severe accidents arise from unanticipated pathways to harm, perhaps in very specific circumstances. (For example, not shutting the bow doors of a ferry properly led to the flooding and capsizing of the Herald of Free Enterprise, killing 193 people.)
Change Impact Analysis
Understanding these connections also allows us to perform safety change impact analysis (‘the analysis of changes within a deployed product or application and their potential consequences’). In many programs I worked on, in-use incidents revealed that:
Designs were not working as intended;
Hazard controls were not as effective as thought;
Work done was not as designed; or that
The actual use of a system was not as foreseen.
If we know the links to something that has changed – what it affects / what affects it – then we can begin to estimate the impact. From experience, this occupies a lot of our time in in-service safety management.
Recovery and Improvement
In the real world things rarely stand still. There are usually many different stimuli for change (we’ve already mentioned our incidents/accidents). Our enterprise might have to raise its game for several reasons:
The Regulator demanding change or improvement;
Customers asking for more performance or more assurance;
The public reaction to incidents elsewhere in the market;
New technology or new competitors in our industry; or
Our commitment to continuous improvement.
Pareto analysis tells us that a minority of causes tend to dominate the effect. Thus, a small number of causes or initiating events drive the occurrence of hazards. Similarly, a minority of hazards will dominate incident and/or accident statistics.
We may know this from experience or analysis of our specific system, or we may have only generic data. It doesn’t matter.
Using these insights, we can use the linkages in the HTS to target particular causes, events, conditions, scenarios, hazards, etc. We identify the set that (should) make the biggest impact, the biggest difference. We can then rank the contributors in order of importance and tackle them.
Again, long and sometimes bitter experience tells me that safety practitioners will spend a lot of time doing this. Reacting to stimuli is a big part of safety management.
The Tool Supports the Process
Of course, we should be using tools to support the process. (The process is designed to produce the results or outcomes that we need). One example of such is the Risk Assessment process from ISO 31000, below.
The Risk Assessment Process
We want our HTS to support this process, storing the data that we get from the risk identification, analysis, and evaluation activities. We also want our Hazard Log to provide information that enables communication and consultation as well as monitoring and review (perhaps using a risk matrix).
Other Functions
Hazard Logs and HTS also perform many other functions. These may appear mundane, but when they go wrong they suddenly become very exciting! What Have Hazard Logs Ever Done for Us? They help us avoid these unwanted excitements, by providing:
Data discipline (e.g. drop-down selections rather than free text fields).
Questions? Comments? Send me your feedback in the comments, below.
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
In ‘Optimizing Safety: Active Hazard Management with Hazard Logs’ we look at how to unleash the power of this underrated tool!
Introduction
A Hazard Log is more than just a record; it’s a dynamic tool for actively managing safety risks associated with systems. This continually updated log encapsulates Hazards, Accident Sequences, and Accidents, ensuring a structured approach to risk management. Dive into the world of Hazard Logs to discover their application, advantages, and best practices for effective use.
Active Management with Hazard Logs
Overview
A Hazard Log serves as an ongoing record, meticulously updated to capture Hazards, Accident Sequences, and Accidents linked to a system. It acts as a comprehensive repository, providing insights into risk management decisions for each Hazard and Accident.
The Hazard Log is a structured method of keeping and referring to Safety Risk Evaluations and other information pertaining to a piece of equipment or system. It is the primary means of monitoring the status of all identified hazards, choices made, and risk-reduction actions done, and should be utilised to assist supervision by the Project Safety Committee and other stakeholders.
Hazards, Accident Sequences, and Accidents noted are those that could potentially occur as well as those that have already occurred. The title Hazard Log may be deceptive because the information saved relates to the overall Safety Programme and includes Accidents, Controls, Risk Evaluation, ALARP/SFARP rationale, and Hazard data.
Utilization and Administration
Administered by a dedicated Hazard Log Administrator, primary access is granted to add, edit, or close data records. All other personnel have read-only access, ensuring visibility of Hazards while maintaining control. Records are tracked using a status field, indicating stages such as opening, awaiting mitigation confirmation, or ALARP/SFARP justification.
Recording Hazards
Considered best practice, each Hazard is recorded as “open,” with ALARP/SFARP arguments treated provisionally until mitigation actions are confirmed. Hazards are not deleted but closed with appropriate justifications, reflecting changes in relevance.
As an example, suppose the mitigation is contingent on the development of an operational procedure. This may not be developed until far after the Hazard has been discovered in the early stages of design or construction.
Hazards should not be erased from the Hazard Log, but rather closed and labeled “out of scope” or “not considered credible” with adequate justification. If such Hazards are no longer thought to be relevant to the system, the Log entry should be modified to reflect this.
Application in Systems
The Hazard Log should focus on a specified system, detailing its scope and safety requirements. It records the evaluation of Hazards, residual risk assessments, and recommendations for mitigation or formal acceptance with ALARP/SFARP justification.
Because a Hazard Log is an organised method of collecting and referencing data and records on Hazards, as well as documenting the Risk Evaluation and other information relevant to an equipment or system, unambiguous cross-referencing to supporting documentation is critical. The supporting documentation can be directly incorporated in the Hazard Log or cross-referenced.
Establishing a Hazard Log: Why and When
Traceability
A Hazard Log is crucial for projects, offering traceability in the decision-making process, and justifying the assessed Safety Risk. Initiated at the program’s earliest stage, it remains a live document throughout the system life cycle.
As modifications are implemented in the system, the Hazard Log should be updated to reflect the current design standard by including new or changed Hazards and the associated residual risks. The Hazard Log must be checked frequently to verify that hazards are being managed effectively and that compelling safety arguments in the Safety Case can be created.
Advantages & Disadvantages
Advantages
The Hazard Log is a traceable record of the Project’s Hazard Management process and thus:
Ensures that the Project Safety Programme uses a consistent set of Safety information;
Facilitates oversight by the Safety Panel and other stakeholders of the current status of the Safety activities; and
Supports the effective management of possible Hazards and Accidents so that the associated Risks are brought up to and maintained at a tolerable level;
Disadvantages
The Hazard Log could include information about the relationship between hazards, accidents, and their control through the establishment and fulfilment of Safety Requirements. However, if it is not robust or well-structured, this may obscure the identification and clearance of Hazards.
If Hazards are not well defined when they are entered into the Hazard Log, the rigour enforced by the need for a clear audit trail of changes made may make it very difficult to maintain the Hazard and Accident records most effectively. Before beginning data entry, an appropriate structure should be created and agreed upon.
Choosing the Right Format: Electronic vs. Paper-Based
Electronic Format
While a Hazard Log can be produced in any format, an electronic format, often in databases like Microsoft Access or SQL Server, ensures quick cross-referencing and traceability. Proprietary tools like Cassandra or spreadsheet packages like Microsoft Excel offer flexibility.
Bespoke vs. Proprietary
Choosing between a bespoke database and a proprietary tool involves considerations of customizability and standardization. A bespoke system may be simple to administer, while a proprietary tool ensures consistency across programs.
In conclusion, Hazard Logs, when actively managed, emerge as indispensable tools for maintaining safety standards and facilitating informed decision-making. Understanding their application and choosing the right format ensures efficient risk management throughout a system’s life cycle.
We will explore more active hazard management in our upcoming blog post using Cassandra as a case study.
That was ‘Optimizing Safety: Active Hazard Management with Hazard Logs’. See another article of my articles on hazard logs here. I hope that you find them useful: leave a comment, below!
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
In this blog post and video ‘Hazard Logs and Hazard Tracking Systems’, I’m going to tell you about their benefits and features.
In many industries, we are required to create a hazard log: perhaps by a regulator, a customer, or a prime contractor. Or maybe it’s “just the way we do it round here”. Whatever the reason, many junior staff will be given responsibility for entering data into a hazard log.
Hazard Logs enable us to manage large amounts of safety data and references, but only if they are implemented properly. Unfortunately, it seems that there are an infinite number of ways of not doing them well. In my 25+ years in System Safety, I’ve seen many bad hazard logs, so I created this lesson to help you get the basics right.
This is the trailer for the full, 35-minute lesson.
Topics
I’m going to be covering these topics, which are the most commonly asked questions:
What is a hazard log? (What is it what do we do with it?)
The key elements of a hazard log (what needs to be in it to make it work)?
Hazard Log management (what we need to do)?
What about hazard log tools? (What can we use to create a hazard log)?
What’s the difference between a hazard log and a risk assessment?
What’s the difference between a hazard log and a risk register?
Transcript
Hi everyone, and welcome to the Safety Artisan.
I’m Simon and today we’re going to be talking about Hazard logs and hazard tracking systems.
As I said, we’re going to look at hazard logs and hazard tracking systems and we’re going to be answering the most popular questions.
The most often asked questions about Hazard logs and Hazard Tracking Systems that you will find on the internet. So that’s what we’re going to answer.
And this is going to be the first of three sessions on this subject.
Side: Topics
Topics for this session. Right now commonly asked questions are:
What is a hazard log? What is it what do we do with it?
The key elements of a hazard log: What needs to be in it to make it work?
Hazard Log of management: What do we need to do?
What about hazard log tools? What can we use to create a hazard log?
Effectively now we’ll be looking at that in much more detail in sessions two and three. But we’ll just go over the basics today and then also, some very common questions:
What’s the difference between a hazard log versus a risk assessment? and
What’s the difference between a hazard log and a risk register?
And when I say Hazard Log, you can substitute [the phrase] hazard tracking system at all times. They’re really one and the same thing, which we will talk about.
See also this info-post on Hazard Logs and there is another post to come on how a relational database can deliver a ‘Full Function’ Hazard Log.
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
The 2023 Digest brings you all The Safety Artisan’s blog posts from last year. I hope that you find this a useful resource! (The final post in the list is the 2022 Digest, which lists another 31 posts.)
In this video lesson, I look at Sub-System Hazard Analysis with Mil-Std-882E (SSHA, which is Task 204). I teach the mechanics of the task, but not just that. I’m using my long experience with this Standard to teach a pragmatic approach to getting the work done. Task 204 is one of three tasks that integrate… Read more: Sub-System Hazard Analysis with Mil-Std-882E
In this 45-minute session, I look at System Hazard Analysis with Mil-Std-882E. SHA is Task 205 in the Standard. I explore Task 205’s aim, description, scope, and contracting requirements. I also provide commentary, based on working with this Standard since 1996, which explains SHA. How to use it to complement Sub-System Hazard Analysis (SSHA, Task… Read more: System Hazard Analysis with Mil-Std-882E
Navigating the Safety Case is Part 4 of a four-part series on safety cases. In it, we look at timing issues and typical content through the safety case lifecycle. A Comprehensive Guide to Ensuring Project Safety When embarking on any significant project, ensuring safety isn’t just a step in the process—it’s the foundation of success.… Read more: Navigating the Safety Case
Introduction In The Lifelong Evolution of a Safety Case, we look at how to Review and revise a Safety Case and Re-Issue a Safety Case Report. When it comes to ensuring safety throughout any Product, System, or Service lifecycle, reviewing and revising the Safety Case isn’t just a recommendation—it’s essential. The age or status of… Read more: The Lifelong Evolution of a Safety Case
The 2024 Blog Digest – Q3/Q4 brings you all of The Safety Artisan’s blog posts from the first six months of this year. I hope that you find this a useful resource! The 2024 Blog Digest – Q3/Q4: 18 Posts! Meet the Author Learn safety engineering with me, an industry professional with 25 years of… Read more: The 2024 Blog Digest – Q3/Q4
In Crafting a Safety Case and Safety Case Report – Part 2, we move on to review and sign off on the artifacts. Introduction In any high-stakes environment—whether it’s defense, engineering, or aviation—Safety Case Reports play an essential role in validating the safety of a system. A meticulous review and sign-off process ensures that these… Read more: Crafting a Safety Case and Safety Case Report – Part 2
Crafting a Safety Case and Safety Case Report: A Comprehensive Guide for Project Safety Assurance – PART 1 [Picture by Eric Bruton from Pexels.com] Introduction Building a robust Safety Case and Safety Case Report is essential to ensuring the safety and regulatory compliance of complex systems within the Ministry of Defence (MOD) and similarly regulated… Read more: Crafting a Safety Case and Safety Case Report
In-Service Safety Management System: Ensuring Long-Term Safety for Military Equipment Safety is paramount when it comes to military operations, especially for in-service equipment relied upon by personnel daily. This article delves into the intricacies of maintaining an In-Service Safety Management System, offering insight into how safety practices are implemented, monitored, and evolved over time. Introduction:… Read more: In-Service Safety Management System
Comprehensive Project Safety Management Plans. Safety is a critical element in any large-scale project, especially in the context of defence and complex systems. One essential tool for managing safety is a Safety Management Plan (SMP). In this article, we’ll break down the process and structure of an effective SMP, highlighting its objectives, content, and how… Read more: Comprehensive Project Safety Management Plans: A Guide
Guide to Running a Project Safety Committee. Okay, so committees are not the sexiest subject, but we need to get stakeholders together to make things happen! Project Safety Committee: Introduction In safety-critical industries such as defense, aerospace, and engineering, maintaining a robust safety management system (SMS) is paramount. A Project Safety Committee (PSC) plays a… Read more: Guide to Running a Project Safety Committee
In ‘Project Safety Initiation’ we look at what you need to do to get your safety project or program started. Introduction Definitions A stakeholder is anyone who will be affected by the introduction of the system and who needs to be consulted or informed about the development and fielding of the system, and anyone who contributes to… Read more: Project Safety Initiation
Members Get a Free Intro Course, 50% Off & Updates. I will send you the links and discount codes via email. So, tick the email box and check your junk mail to receive the offers. You will get an email series showcasing the free/paid resources. Also, regular updates on new articles: never miss another post!… Read more: Members Get a Free Intro Course, 50% Off & Updates
Welcome to Module Five, More Resources for Risk Assessment. We’re on the home straight now! This is the last of the five modules. I will let you know where to get more resources and help on these topics. Course Learning Objectives More Resources for Risk Assessment: Transcript Copyright/Source Statement “First, I want to point out… Read more: More Resources for Risk Assessment
Designing Your Risk Assessment Program. Which Ingredients should we use? In this post, I draw upon my 25+ years in system safety to give you some BOLD advice! I’m going to dare to suggest which analysis tasks are essential to every System Safety Program. I also suggest which tasks are optional depending on the system… Read more: Designing Your Risk Assessment Program
When Understanding Your Risk Assessment Standard, we need to know a few things. The standard is the thing that we’re going to use to achieve things – the tool. And that’s important because tools designed to do certain things usually perform well. But they don’t always perform well on other things. So we will ask,… Read more: Understanding Your Risk Assessment Standard
Welcome to Risk Management 101, where we’re going to go through these basic concepts of risk management. We’re going to break it down into the constituent parts and then we’re going to build it up again and show you how it’s done. I’ve been involved in risk management, in project risk management, safety risk management,… Read more: Risk Management 101
In this module, System Safety Risk Analysis, we’re going to look at how we deal with the complexity of the real world. We do a formal risk analysis because real-world scenarios are complex. The Analysis helps us to understand what we need to do to keep people safe. Usually, we have some moral and legal obligation to do it as well. We need to do it well to protect people and prevent harm to people.
TL;DR Updating Legal Presumptions for Computer Reliability must happen if we are to have justice! Background The ‘Horizon’ Scandal in the UK was a major miscarriage of justice: Between 1999 and 2015, over 900 sub postmasters were convicted of theft, fraud and false accounting based on faulty Horizon data, with about 700 of these prosecutions… Read more: Updating Legal Presumptions for Computer Reliability
What are the Hazard and Risk basics? So, what is this risk analysis stuff all about? What is ‘risk’? How do you define or describe it? How do you measure it? When? Why? Who…? In this free session, I explain the basic terms and show how they link together, and how we can break them… Read more: Hazard and Risk Basics
This post, ‘SSRAP: Start the Course’, gives an overview of System Safety Risk Assessment Programs. It describes the Learning Objectives of the Course and its five modules. We’re going to learn how to: This post is part of a series: SSRAP: Start of the Course – Transcript Welcome to this course on System Safety Risk… Read more: SSRAP: Start the Course
In this post, we will look at Three Insightful Methods for Causal Analysis. Only three?! If you search online, you will probably find eight methods coming up: However, not all these methods are created equal! Only some provide real insight to the challenge of causal analysis. So, I’ve picked the best ones – based on… Read more: Three Insightful Methods for Causal Analysis
In this ‘Introduction to System Safety Risk Assessment’, we will pull together several key ideas. First, we’ll talk about System Safety. This is safety engineering done in a Systems Engineering Framework. We are doing safety within a rigorous process. Second, we’re talking about Risk Assessment. This is a term for putting together different activities within… Read more: Introduction to System Safety Risk Assessment
The 2024 Blog Digest – Q1/Q2 brings you all of The Safety Artisan’s blog posts from the first six months of this year. I hope that you find this a useful resource! The 2024 Blog Digest – Q1/Q2: 25 Posts! There’s More! Head over to my Thinkfic Site for courses & webinars. Subscribe for a… Read more: The 2024 Blog Digest – Q1/Q2
That’s the 2023 Digest – look out for much more in 2024!
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
Hi, everyone, and welcome to The Safety Artisan. I’m Simon, and I just wanted to share with you briefly why I started this enterprise. I’ve had a career in safety, engineering, and safety consulting for over 25 years now. And in that time, I’ve seen customers make one of two mistakes quite often. First of all, I’ve seen customers not do some things that they should have been doing. This was usually because they were just ignorant of what their legal obligations were.
And I guess that’s a fairly obvious mistake. That’s what you would expect me to say. But more often, I’ve seen customers do too much to try and achieve safety, which is surprising! I’ve seen people waste a lot of time, energy, and money doing things that just didn’t make a difference. Sometimes it actually got in the way of doing good safety work.
And I think the reasons for those mistakes are, first of all, ignorance.
Secondly, not knowing precisely what safety is and therefore not being able to work out how to get there. That’s why I started The Safety Artisan. I wanted to equip people with the knowledge of what safety really is and the tools to get there efficiently. To neither do too much nor too little. We want Safety, Just Right.
This is the first in a new series of blog posts on Principles of Software Safety Assurance. In it, we look at the 4+1 principles that underlie all software safety standards.
We outline common software safety assurance principles that are evident in software safety standards and best practices. You can think of these guidelines as the unchanging foundation of any software safety argument because they hold across projects and domains.
The principles serve as a guide for cross-sector certification and aid in maintaining comprehension of the “big picture” of software safety issues while evaluating and negotiating the specifics of individual standards.
In this first of six blog posts, we introduce the subject and the First Principle.
Why Software Safety Principles?
I’ve been involved with industrial-scale software projects since 1994, and the concept of ‘principles’ is valuable for two reasons.
First, many technical people like detail and quickly bypass concepts to get to get to their comfort zone. This means that we often neglect the ‘big picture’ and are uncomfortable making high-level judgments. In turn, this makes it difficult for us to explain or justify our choices to management or other stakeholders.
The second reason is similar to the first. In the guts of a standard, we can think in terms of compliance with detailed requirements and our choices become simple – black and white. This is easy, but it does not equip us to choose between standards or help us to argue that an alternative means of compliance is valid. Thus, ‘Is this good enough?’ is not a question that we find easy to answer.
Introduction
Software assurance standards have increased in number along with the use of software in safety-critical applications. There are now several software standards, including the cross-domain ‘functional safety’ standard IEC 61508, the avionics standard DO-178B/C, the railway application CENELEC-50128, and the automotive application ISO26262. (The last two are derivatives of IEC 61508.)
Unfortunately, there are significant discrepancies in vocabulary, concepts, requirements, and suggestions among these standards. It could seem like there is no way out of this.
However, the common software safety assurance principles that can be observed from both these standards and best practices are few (and manageable). These concepts are presented here together with their justification and an explanation of how they relate to current standards.
These ideas serve as the unchanging foundation of any software safety argument since they hold across projects and domains. Of course, accepting these principles does not exempt one from adhering to domain-specific norms. However, they:
Provide a reference model for cross-sector certification; and
Aid in maintaining comprehension of the “big picture” of software safety issues;
While analyzing and negotiating the specifics of individual standards.
Software Safety Principles
Principle 1: Requirements Validity
The first software safety assurance principle is:
Principle 1: Software safety requirements shall be defined to address the software contribution to system hazards.
‘The Principles of Software Safety Assurance’, RD Hawkins, I Habli & TP Kelly, University of York.
The evaluation and reduction of risks are crucial to the design of safety-critical systems. When specific environmental factors come into play, system-level dangers like unintentional braking release in cars and the absence of stall warnings in aircraft can result in accidents. Although conceptual, software can implement system control or monitoring features that increase these risks (e.g. software implementing antilock braking or aircraft warning functions).
Typically, the system safety assessment process uses safety analysis methodologies like Fault Tree Analysis or Hazard and Operability (HAZOP) Studies to pinpoint how software, along with other components like sensors, actuators, or power sources, can contribute to risks. The results of these methodologies ought to influence the formulation of safety requirements and their distribution among software components.
It is crucial for us to remember that software is now considered a black box, utilized to enable specific functions, and with limited visibility into how these functions are implemented. The risk from some system hazards can rise to unacceptable levels if hazardous software failures are not identified and suitable safety standards are not defined and applied.
Examples of software requirements not being adequately defined – and the effects thereof – were reported by the US Federal Drug Authority (FDA).
Simply put, software is a fundamental enabling technology employed in safety-critical systems. Assessing how software might increase system risks should be a crucial component of the overall system safety process. We define safety standards to minimize hazardous software contributions that are discovered in a safety process, which addresses these contributions.
These contributions must be described in a clear and testable way, namely by identifying the exact types of software failures that can result in risks. If not, we run the risk of creating generic software safety requirements—or even just correctness requirements—that don’t take into account the specific hazardous failure modes that have an impact on the system’s safety.
Principles of Software Safety Assurance: End of Part 1 (of 6)
I based this blog post on the paper ‘The Principles of Software Safety Assurance’, RD Hawkins, I Habli & TP Kelly, University of York. The original paper is available for free here. I learned safety engineering from Tim Kelly, and others, at the University of York. I am so glad that I can share their valuable work in a more accessible format.
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
Principles of Software Safety Training
Learn more about this subject in my course ‘Principles of Safe Software’ here. The next post in the series is here.
My course on Udemy, ‘Principles of Software Safety Standards’ is a cut-down version of the full Principles Course. Nevertheless, it still scores 4.42 out of 5.00 and attracts comments like:
“It gives me an idea of standards as to how they are developed and the downward pyramid model of it.” 4* Niveditha V.
“This was really good course for starting the software safety standareds, comparing and reviewing strengths and weakness of them. Loved the how he try to fit each standared with4+1 principles. Highly recommend to anyone that want get into software safety.” 4.5* Amila R.
“The information provides a good overview. Perfect for someone like me who has worked with the standards but did not necessarily understand how the framework works.” 5* Mahesh Koonath V.
“Really good overview of key software standards and their strengths and weaknesses against the 4+1 Safety Principles.” 4.5*Ann H.
Lessons Learned: In this 30-minute video, we learn lessons from an accident in 2016 that killed four people on the Thunder River Rapids Ride in Queensland. The coroner’s reportwas issued this year, and we went through the summary of that report. In it, we find failings in WHS Duties, Due Diligence, risk management, and failures to eliminate or minimize risks So Far As is Reasonably Practicable (SFARP). We do not ‘name and shame’, rather we focus on where we can find guidance to do better.
In 2016, four people died on the Thunder River Rapids Ride.
Lessons Learned: Key Points
We examine multiple failings in:
WHS Duties;
WHS Due Diligence;
Risk management; and
Eliminating or minimizing risks So Far As is Reasonably Practicable (SFARP).
Transcript: Lessons Learned from a Theme Park Tragedy
Introduction
Hello, everyone, and welcome to the Safety Artisan: purveyors of fine safety engineering training videos and other resources. I’m Simon, and I’m your host, and today we’re going to be doing something slightly different. So, there are no PowerPoint slides. Instead, I’m going to be reading from a coroner’s report from a well-known accident here in Australia, and we’re going to be learning some lessons in the context of WHS workplace health and safety law.
Disclaimer
Now, I’d just like to reassure you before we start that I won’t be mentioning the names of the deceased. I won’t be sharing any images of them. And I’m not even going to mention the firm that owned the theme park because this is not about bashing people when they’re down. It’s about us as a community learning lessons when things go wrong to fix the problem, not the blame. So that’s what I’d like to emphasize here.
The Coroner’s Report
So, I’m just going to I’m just turning to the summary of the coroner’s report. The coroner was examining the deaths of four people back in 2016 on what was called the Thunder River Rapids Ride. Or TRRR or TR3 for short because it’s a bit of a mouthful. This was a water ride, as the name implies, and what went wrong was that the water level dropped. Rafts, these circular rafts that went down the rapids, went down the chute, got stuck. Another raft came up behind the stuck raft and went into it. One of the rafts tipped over. These rafts seat six people in a circular configuration. You may have seen them. They’re in – different versions of this ride are in lots of theme parks.
But out of the six, unfortunately, the only two escaped before people were killed, tragically. So that’s the background. That happened in October 2016. The coroner’s report came out a few months ago, and I’ve been wanting to talk about it for some time because it illustrates very well several issues where WHS can help us do the right thing.
WHS Duties
So, first of all, I’m looking at the first paragraph in the summary, the coroner starts off; the design and construction of the TRRR at the conveyor and unload area posed a significant risk to the health and safety of patrons. Notice that the coroner says the design and construction. Most people think that WHS only applies to workplaces and people managing workplaces, but it does a lot more than that. Sections 22 through 26 of the Act talk about the duties of designers, manufacturers, importers, suppliers, and then people who commissioned, installed, et cetera.
So, WHS supplies duties on a wide range of businesses and undertakings, and designers and constructors are key. There are two of them. Now, it’s worth noting that there was no importer here. The theme park, although the TRRR ride was similar to a ride available commercially elsewhere, for some reason, they chose to design and build their version in Queensland. Don’t know why. Anyway, that doesn’t matter now. So, there was no importer, but otherwise, even if you didn’t design and construct the thing, if you imported it, the same duties still apply to you.
No Effective Risk Assessment
So, the coroner then goes on to talk about risks and hazards and says each of these obvious hazards posed a risk to the safety of patrons on the ride and would have been easily identifiable to a competent person had one ever been commissioned to conduct a risk and hazard assessment of the ride. So, what the coroner is saying is, “No effective risk assessment has been done”. Now, that is contrary to the risk management code of practice under WHS, and also, of course, the definition of SFARP, so far as reasonably practicable, basically is a risk assessment or risk management process. So, if you’ve not done effective risk management, you can’t say that you’ve eliminated or minimized risks, SFARP, which is another legal requirement. So, a double whammy there.
Then moving on. “Had noticed been taken of lessons learned from the preceding incidents, which were all of a very similar nature …” and then he goes on. That’s the back end of a sentence where he says, “You didn’t do this, you had incidents on the ride, which are very similar in the past, and you didn’t learn from them.” And again, concerning reducing risks, Section 18 in the WHS Act, which talks about the definition of reasonably practicable, which is the core of SFARP, talks about what ought to have been known at the time.
So, when you’re doing a risk assessment, or maybe you’re reassessing risk after a modification – and this ride was heavily modified several times, or after an incident – you need to take account of the available information. And the owners of TRRR, the operators, didn’t do that. So, another big failing.
The coroner goes on to note that records available concerning the modifications to the ride are scant and ad hoc. And again, there’s a section in the WHS risk management code of practice about keeping records. It’s not that onerous. I mean, the COP is pretty simple, but they didn’t meet the requirements of the code of practice. So, bad news again.
Due Diligence
And then finally, I’ve got to the bottom of page one. So, the coroner then notes the maintenance tasks undertaken on the ride, while done so regularly and diligently by the staff, seemed to have been based upon historical checklists which were rarely reviewed despite the age of the device or changes to the applicable Australian standards. Now, this is interesting. So, this is contravening a different section of the WHS Act.
Section 27 of the WHS Act talks about the duties of officers, and effectively that sort of company directors and senior managers. Officers are supposed to exercise due diligence. In the act, due diligence is fairly simple- It’s six bullet points, but one of them is that the officers have to sort of keep up to date on what’s going on in their operation. They have to provide up-to-date and effective safety information for their staff. They’re also supposed to keep up with what’s going on in safety regulations that apply to their operation. So, I reckon in that one statement from the coroner, then there’s probably three breaches of due diligence there to start with.
Risk Controls Lacking
We’ve reached the bottom of page one- Let’s carry on. The coroner then goes on to talk about risk controls that were or were not present and says, “In accordance with the hierarchy of controls, plant and engineering measures should have been considered as solutions to identified hazards”. So in WHS regulations, and it’s repeated in the risk code of practice, there’s a thing called the hierarchy of controls. It says that some types of risk controls are more effective than others and therefore they come at the top of the list, whereas others are less effective and should be considered last.
So, top of the list is, “Can you eliminate the hazard?” If not, can you substitute the hazardous thing for something else that’s less hazardous- or with something else that is less hazardous, I should say? Can you put in engineering solutions or controls to control hazards? And then finally, at the bottom of my list are admin procedures for people to follow, and then personal protective equipment for workers, for example. We’ll talk about this more later, but the top end of the hierarchy had just not been considered or not effectively anyway.
A Predictable Risk
So, the coroner then goes on to say, “Rafts coming together on the ride was a well-known risk, highlighted by the incident in 2001 and again in 2004”. Now, actually, it says 2004. I think that might be a typo. Elsewhere, it says 2014, but certainly, two significant incidents were similar to the accident that killed four people. And it was acknowledged that various corrective measures could be undertaken to, quote, “adequately control the risk of raft collision”.
However, a number of these suggestions were not implemented on the ride. Now, given that they’ve demonstrated the ability to kill multiple people on the ride with a raft collision, it’s going to be a very, very difficult thing to justify not implementing controls. So, given the seriousness of the potential risk, to say that a control is feasible is practicable, but then to say “We’re not going to do it. It’s not reasonable”. That’s going to be very, very difficult to argue, and I would suggest it’s almost a certainty that not all reasonably practicable controls were implemented, which means the risk is not SFARP, which is a legal requirement.
Further on, we come back to document management, which was poor with no formal risk register in place. So, no evidence of a proper risk assessment. Members of the department did not conduct any holistic risk assessments of rides with the general view that another department was responsible. So, the fact that risk assessment wasn’t done – that’s a failure. The fact that senior management didn’t knock heads together and say, “This has to be done. Make it happen.” That’s also another failing. That’s a failing of due diligence, I suspect. So, we’ve got a couple more problems there.
High-Risk Plant
Then, later on, the coroner talks about the necessary engineering oversight of high-risk plant not being done. Now, under the WHS Act definitions, amusement rides are counted as high-risk plant, presumably because of the number of serious accidents that have happened with them over the years. The managers of the TRRR didn’t meet their obligations concerning high-risk plants. So, some things that are optional for common stuff are mandatory for high-risk plants, and those obligations were not met, it seems.
And then in just the next paragraph, we reinforce this due diligence issue. Only a scant amount of knowledge was held by those in management positions, including the general manager of engineering, as to the design modifications and past notable incidents on the ride. One of the requirements of due diligence is that senior management must know their operations and know the hazards and risks associated with the operations. So, for the engineering manager to be ignorant about modifications and risks associated with the ride, I think, is a clear failure of due diligence.
Still talking about engineering, the coroner notes, “it is significant that the general manager had no knowledge of past incidents involving rafts coming together on the ride”. Again, due diligence. If things have happened, those need to be investigated and learned from, and then you need to apply fresh controls if that’s required. And again, this is a requirement. So, this shows a lack of due diligence. It’s also a requirement in the risk management code of practice to look at things when new knowledge is gained. So, a couple more failures there.
No Water-Level Detection, Alarm, Or Emergency Stop
Now, it said that the operators of the ride were well aware that when one pump failed, and there were two, the ride was no longer able to operate with the water level dropping dramatically, stranding the rafts on the steel support railings. And of course, that’s how the accident happened. Regardless, there was no formal means by which to monitor the water level of the ride and no audible alarm to advise that one of the pumps had ceased to operate. So, a water level monitor? Well, we’re talking potentially about a float, which is a pretty simple thing. There’s one in every cistern, in every toilet in Australia. Maybe the one for the ride would have to be a bit more sophisticated than that – a bit industrial grade – but the same principle.
And no alarm to advise the operators that this pump had failed, even though it was known that this would have a serious effect on the operation of the ride. So, there are multiple problems here. I suspect you’ll be able to find regulations that require these things. Certainly, if you looked at the code of practice on plant design, because this counts as an industrial plant, it’s a high-risk plant, so you would expect very high standards of engineering controls on high-risk plants, and these were missing. More on that later.
In a similar vein, the coroner says “a basic automated detection system for the water level would have been inexpensive and may have prevented the incident from occurring”. So basically, the coroner is saying this control mechanism would have been cheap, so it’s certainly reasonably practicable. If you’ve got a cheap control that will prevent a serious injury or death, then how on earth are you going to argue that it’s not reasonable to implement it? The onus is on us to implement all reasonably practical controls.
And then similarly, the lack of a single emergency stop on the ride, which was capable of initiating a complete shutdown of all the mechanisms, was also inadequate. And that’s another requirement from the code of practice on plant design, which refers back to WHS regulations. So, another breach there.
Human Factors
We then move on to a section where it talks about operators, operators’ accounts of the incident, and other human factors. I’m probably going to ask my friend Peter Bender, who is a Human Factors specialist, to come and do a session on this and look at this in some more detail, because there are rich pickings in this section, and I’m just going to skim the surface here because we haven’t got time to do more.
The coroner says “it’s clear that these 38 signals and checks to be undertaken by the ride operators were excessive, particularly given that the failure to carry out any one could potentially be a factor which would contribute to a serious incident”. So clearly, 38 signals and checks were distributed between two ride operators, because there was no one operator in control of the whole ride- that’s a human factors nightmare for a start- but clearly, the work designed for the ride was poor. There is good guidance available from Safe Work Australia on good work design, so there’s no excuse for this kind of lapse.
And then the coroner goes on to say, reinforcing this point that the ride couldn’t be safely controlled by a human operator. The lack of engineering controls on a ride of this nature is unjustifiable. Again, reinforces the point that risk was not SFARP because not all reasonably practicable controls had been implemented. Particularly controls at the higher end of the hierarchy of controls. So, a serious failing there.
(Now, I’ve got something that I’m going to skip, actually, but – It’s a heck of a comment, but it’s not relevant to WHS.)
Training And Competence
We’re moving on to training and competence. Those responsible for managing the ride whilst following the process and procedure in place, and I’m glad to see you from a human practice point of view that the coroner is not just trying to blame the last person who touched it. He’s making a point of saying the operators did all the right stuff. Nevertheless, they were largely not qualified to perform the work for which they were charged.
The process and procedures that they were following seemed to have been created by unknown persons. Because of the poor record-keeping, presumably, it is safe to assume lacked the necessary expertise. And I think the coroner is making a reasonable assumption there, given the multiple failings that we’ve seen in risk management, in due diligence, in record-keeping, in the knowledge of key people, et cetera, et cetera. It seems that the practice at the park was simply to accept what had always been done in terms of policy and procedure.
And despite changes to safety standards and practices happening over time, because this is an old ride, only limited and largely reactionary consideration was ever given to making changes, including training provided to staff. So, reactionary -bad word. We’re supposed to predict risk and prevent harm from happening. So, multiple failures in due diligence here and on staff training, providing adequate staff training, providing adequate procedures, et cetera.
The coroner goes on to say, “regardless of the training provided at the park, it would never have been sufficient to overcome the poor design of the ride. The lack of automation and engineering controls”. So, again, the hierarchy of controls was not applied, and relatively cheap engineering controls were not used, placing an undue burden on the operator. Sadly, this is all too common in many applications. This is one of the reasons they are not naming the ride operators or trying to shame them, because I’ve seen this happen in so many different places. It wouldn’t be fair to single these people out.
‘Incident-Free’ Operations?
Now we have a curious, a curious little statement in paragraph 1040. The coroner says “submissions are made that there was a 30-year history of incident-free operation of the ride”. So, what it looks like is that the ride operators and management are trying to tell the coroner that they never had an incident on the ride in 30 years, which sounds pretty impressive, doesn’t it, at face value?
But of course, the coroner already knew or discovered later on that there had been incidents on the ride. Two previous incidents were very similar to the fatal accident. Now, on the surface, this looks bad, doesn’t it? It looks like the ride management was trying to mislead the coroner. I don’t think that’s the case because I’ve seen many organizations do poor incident reporting, poor incident recording, and poor learning from experience from incidents. It doesn’t surprise me that the senior management was not aware of the incidents on their ride. Unfortunately, it’s partly human nature.
Nobody likes to dwell on their failures or think about nasty things happening, and nobody likes to go to the boss saying we need to shut down a moneymaking ride. Don’t forget, this was a very popular ride. We need to shut down a moneymaking ride to spend more money on modifications to make it safer. And then management turns around and says, “Well, nobody’s been hurt. So, what’s the problem?” And again, I’ve seen this attitude again and again, even on people operating much more sophisticated and much more dangerous equipment than this. So, whilst this does look bad- the optics are not good, as they like to say. I don’t think there’s a conspiracy going on here. I think it’s just stupid mistakes because it’s so common. Moving on.
Standards
Now the coroner goes on to talk about standards not being followed, particularly when standards get updated over time. Bearing in mind that this ride was 30 years old. The coroner states, “it is essential that any difference in these standards is recognized and steps taken to ensure any shortfalls with a device manufactured internationally are managed”. Now, this is a little bit of an aside, because as I’ve mentioned before, the TRRR was actually designed and manufactured in Australia. Albeit not to any standards that we would recognize these days. But most rides were not, and this highlights the duties of importers. So, if you import something from abroad, you need to make sure that it complies with Australian requirements. That’s a requirement, that’s a duty under WHS law. We’ll come back to this in just a moment.
The Role Of The Regulator
We’ll skip that one because we’ve done training and competency to death. So, following on about the international standards, the coroner also has a crack at the Queensland regulator, who I won’t name, and says, “the regulator draws my attention to the difficulties arising when we’re requiring all amusement devices to comply with Australian standards. This difficulty is brought about by the fact that most amusement devices are designed and manufactured overseas, predominantly based on European standards”. [Actually, WHS law generally does NOT require us to comply with Australian Standards!]
Now, in the rest of the report, the coroner has a good old crack at the regulator. The coroner sticks the boot into the regulator for being pretty useless. And sadly, that’s no surprise in Australia. So basically, the regulator said, “Oh, it’s all too difficult!” And you think, “Well, it’s your job, actually, so why haven’t you done it properly?”
But being a little bit more practical, if you work in an industry where a lot of stuff is imported, and let’s face it, that’s pretty common in Australia, you’ve got two choices. You can either try to change Australian standards so that they align better with the standards of the kit where you’re getting the stuff from in your industry, or maybe the regulators could say, “Okay, this is a common problem across the industry. We will provide some guidance that tells you how to make that transition from the international standards to Australian standards and what we as the regulator consider acceptable and not acceptable”. And then that helps the industry to do the right thing and to be consistent in terms of operation and enforcement.
So, the regulator is letting people who they regulate know this is the standard that is required of you, this is what you have to do. And that’s the job of a good regulator. So, the fact that the regulator in this particular case just hadn’t bothered to do so for some decades, it would seem, doesn’t say a lot about the professionalism of the regulator. And I’m not surprised that the coroner decided to have a go at them.
Summary
So, we’ve been through just over 20 comments, I think. I mean, I had 24/25 in total, but I skipped a few because they were a bit repetitive, and it’s interesting to note that there were two major comments on failure to conduct designer duties and that kind of thing. Seven on risk management, four on SFARP, although of course, all the risk management ones also affect SFARP, and five on due diligence. So, there are almost 20 significant breaches there, and I wasn’t even really trying to pick up everything the coroner said. And bearing in mind, I was only reading from the summary. I didn’t bother reading the whole report because it’s pages and pages and pages.
And the lesson that we can draw from this, friends, is not to bash the people who make mistakes, but to learn lessons for ourselves. How could we do better? And I think the lesson is that everything that we need to do has been set out in the WHS Act, in the WHS regulations. Then there are codes of practice that give us guidance in particular areas and our general responsibilities, and these codes of practice also guide us on what should be considered, SFARP, for certain hazards and risks. There’s also some fantastic guidance, documentation, and information available from Safe Work Australia. On, for example, human factors, good work design, and so on.
So, there’s lots of really good, really readable information out there, and it’s all free. It’s all available on that wonderful thing we call the Internet. So, there is no excuse for making basic mistakes like this and killing people. It’s not that difficult. And a lot of the safety requirements are not that onerous. You don’t have to be a rocket scientist to read and understand them. A lot of the requirements are basic, structured common sense.
So, the lesson from this awful accident is that it doesn’t have to be this way. We can do much better than that quite easily, and if we don’t and something goes wrong, then the law will be after us. It will be interesting to see- I believe that WorkSafe Queensland is now investigating to see whether they’re going to bring any prosecutions that should be said. The police investigated and didn’t bring any prosecutions against individuals. I don’t know if Queensland has a corporate manslaughter act. I wouldn’t think so based on the fact that they’ve not prosecuted anybody, but you don’t need to find an individual guilty of gross negligence or manslaughter for four WHS to take effect.
So, I suspect that in due course, we will see the operators of the theme park probably cop a significant fine, and maybe some of their directors and senior managers will be going to jail. That’s how serious these breaches are and how numerous they are. You don’t need to dig very deep to see what’s gone wrong and to see that the legal obligations have not been met.
Meet the Author
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
Understanding System Safety Engineering: A Quick Guide, takes you through some key points of this complex subject.
Introduction
System safety engineering plays a crucial role in ensuring the safety of complex systems. In this post, we will explore the fundamental concepts of system safety engineering and its importance in the realm of systems engineering.
System Safety Engineering Explained
System safety engineering, as the name implies, focuses on engineering safety within a systems-engineering context. It involves deliberately integrating safety measures into the framework of complex systems.
Read on, or watch this short video for some pointers:
What is System Safety Engineering?
Key Points of System Safety Engineering
1. Consider the Whole System
In system safety engineering, a holistic approach is essential. It’s not just about hardware and technical aspects; it includes software, operating environments, functions, user interactions, and data. This comprehensive view aligns with systems theory, ensuring a thorough safety assessment.
2. A Systematic Process
System safety engineering follows a systematic process. Starting with high-level requirements, it meticulously analyzes potential risks, safety obligations, and components. The V model illustrates this structured approach, emphasizing the importance of verification and validation at every stage.
The Systems Engineering ‘V’ Model
3. Emphasis on Requirements
Unlike simple commodities like toasters, complex systems require rigorous requirement analysis. System engineers meticulously decompose the system, defining boundaries, interactions, and functionalities. These requirements undergo rigorous validation, minimizing surprises and ensuring safety from the start.
Bowtie showing the Foundations of System Safety
4. Think Safety from the Start
A significant aspect of system safety engineering is the early integration of safety considerations. By addressing safety concerns right from the beginning, potential issues are identified and resolved cost-effectively. This proactive approach enhances the overall safety of the system.
Which way should we go?
Summary
In summary, system safety engineering is characterized by its systematic approach to understanding the entire system, following a structured process, and integrating concepts from systems engineering and systems theory. By focusing on comprehensive requirements and thinking about safety from the start, system safety engineering ensures the safety and reliability of complex systems.
Meet the Author
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
Meet the Author
If you found this helpful, there’s more depth in this article, and you can also see System Safety FAQ. There’s a low-price introductory course on the System Safety Process – on Udemy (please use this link, otherwise Udemy takes two-thirds of the revenue).
In System Safety FAQs, I will deal with the most commonly searched-for online queries. This post is also the basis for the First in a new series of monthly webinars I’m running. I will also be answering your questions: leave them in the comments at the bottom of this post!
What is System Safety?
“System Safety is the application of engineering and management principles, criteria and techniques to achieve acceptable mishap risk within the constraints of operational effectiveness and suitability, time and cost throughout all phases of the system life cycle.”
NASA
This definition from NASA is spot on. System Safety is fundamentally about reducing the risks of mishaps (accidents). The NASA Office of Safety and Mission Assurance website is great for practitioners!
The Systems Engineering ‘V’ Model
“The system safety concept calls for a risk managementstrategy based on identification, analysis of hazards and application of remedial controls using a systems-based approach”.[1]
Wikipedia
This Wikipedia article reminds us that safety risk management is a subset of risk management in general. It also brings in the concept of a ‘hazard’, which is typical for ‘system safety’ – see my free lesson on basic risk concepts for more information.
Where Does Safety Start?
Safety is an ‘emergent property’, that is, it comes about by pulling together many different things. Only leaders and managers can deliver these things; it doesn’t work if you try to do it from the bottom up.
“Safety undoubtedly starts at the top. The people leading the organization are the ones most responsible for its safety. It’s simple.”
I would also say that safety begins at the start of the lifecycle with requirements – see my short video about what System Safety is:
Safe System Approach?
“The Safe System approach adopts a holistic view of the road transport system and the interactions between people, vehicles, and the road environment. It recognises that people will always make mistakes and may have road crashes – but those crashes should not result in death or serious injury.”
This is a great view of a safe system approach, or strategy, from the world of road safety. Road networks, their commercial and private users, neighbours, regulators, emergency services, etc., form a very complex distributed system.
Why System Safety?
What are the benefits?
“A customised Safety Management System will help you create an environment where all employees are empowered to identify hazards before they become problems, so your business can stay safe without losing focus on growth, profit or innovation.”
I would add that a systematic approach to safety saves time and money in the long run.
System Safety for The 21st Century
Traditional System Safety has its critics, most famously professors Nancy Leveson and Erik Hollnagel. They have made various criticisms of system safety – some of which I agree with, and some I most definitely do not.
System-Theoretic Accident Model and Processes (STAMP);
Systems Theoretic Process Analysis (STPA); and
Causal Analysis using System Theory (CAST) – accident analysis.
Hollnagel has written on a wide variety of safety topics, including cognition, organisational robustness, and resilience. He also coined the terms “Safety I” for traditional safety approaches and “Safety II” to describe the conceptual approach that he and others have developed.
He designed the Functional Resonance Analysis Method (FRAM).
“THE FRAM is a method to analyse how work activities take place either retrospectively or prospectively. This is done by analysing work activities in order to produce a model or representation of how work is done.”
I have tried FRAM, and even without any training (which is recommended), I found it tremendously powerful. FRAM can analyse problems that conventional safety techniques just can’t get to grips with.
From ‘FRAM in a Nutshell’ by Mohammad Tishehzan at etn-peter.eu
Others have also introduced the term “Safety III”, but I’m not sure how useful these labels are. Perhaps we are now on a trajectory of diminishing returns.
System Safety is a Design Parameter
To save us from all this abstract navel-gazing, let’s get back to practical matters.
“Safety-related parameters are control system variables whose incorrect setting immediately increases the risk to the user.”
Concrete, specific, practical: I love it! Let’s not forget that we do safety for a reason, and a big part of that is to control the machines that make our modern world. This doesn’t sound very exciting, but automation has enabled huge increases in productivity, wealth, health, quality of life, lifespan and human rights. Let’s remember that during the current hysteria about Artificial Intelligence (actually Machine Learning).
Safety System of Work
“a safe system of work such as safety procedures. information, supervision, instruction and training on the safe use, handling and storage of machinery, structures, substances and other work tasks. personal protective equipment as required. a system to identify hazards, assess and control risks.”
If we think about it, this ties in nicely with the definition of a system used in system safety, e.g.:
“A combination, with defined boundaries, of elements that are used together in a defined operating environment to perform a given task or achieve a specific purpose. The elements may include personnel, procedures, materials, tools, equipment, facilities, services and/or software as appropriate.”
UK Defence Standard 00-56/1
System Safety in Engineering
There are a number of ways that we could answer this (implicit) question. Here’s one from the Office of The Under Secretary Of Defense For Research and Engineering:
“System safety engineering involves planning, identifying, documenting, and mitigating hazards that contribute to mishaps involving defense systems, platforms, or personnel (military and the public). The system safety practice aids in optimizing the safety of a system.”
This definition neatly pulls together activities, hazards and accidents, those impacted and the aim of the whole thing. Phew!
There’s More!
Questions and Comments?
Please leave them below.
Meet the Author
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!
I’ve just passed the Certified Information Systems Security Professional (CISSP) Exam…
Get the full ‘My CISSP Exam Journey’ free video here.
I’ve just passed the Certified Information Systems Security Professional (CISSP) Exam, which was significantly updated on 1st May 2021. In this 30-minute video, I will cover:
The official CISSP course and course guide;
The 8 Domains of CISSP, and how to take stock of your knowledge of them;
The official practice questions and the Study Guide;
The CISSP Exam itself; and
Lessons learned from my journey.
I wish you every success in your CISSP journey: it’s tough, but you can do it!
Transcript: My CISSP Exam Journey
Hi, Everyone,
My name is Simon Di Nucci and I’ve just passed the new CISSP exam; for those of you who don’t know what that is, that’s the Certified Information Systems Security professional. It’s new because the exams have been around a long time, but the syllabus and the exam itself have undergone a significant change as of the 1st of May this year. I’m probably one of the first people to pass the new exam, which I have to tell you was a great relief because it was really it was a tough exam and it was tough preparing for it.
It was a big mountain to climb. I am very, very relieved to have passed. Now, I hope to share some lessons with you. When I mentioned that I passed on the cybersecurity groups on Facebook and LinkedIn, I got a huge response from people who appreciated how difficult it is to do this and also lots of questions. And whilst I can’t talk about the specifics of the exam, that’s not allowed, I can share some really useful lessons learned from my journey.
Introduction
So I’m going to be talking about what I did:
The Official Course, and the Student Guide;
How I took stock at the start of the revision process;
How I revised using the practice questions and the Study Guide;
Something about the exam itself; and
Lessons learned.
The Official Course
So let’s get on with it. My journey was that two or three years ago, the firm that I worked for decided that they wanted me to take the CISSP exam in order to improve our credibility when doing cybersecurity, and my credibility.
I was sent on a five-day course, which was very intense, and it was the official book.is the official ISC2 course. And that was several hundred slides a day for five days. It was very intense. And as you can see, the guy that you get with a pretty hefty eight hundred pages of closely packed and high-quality material. I was taught by someone who was clearly a very experienced expert in the field.
It was a good quality course. It cost about $3,700 (Australian). I think that’s about $2,500 (US). In terms of the investment, I think it was worth it because it covered a lot of ground, and I was very rusty on a lot of this stuff. It was it was a useful ‘crammer’ to get back into this stuff. As I said, [the Study Guide is] 800 pages long. I’ve done a lot of revising!
Practical Things
Let’s put that to one side. The course was very good, but of course, it takes some time out of your schedule to do it. You need the money and the support from your workplace to be able to do that. There are now online courses, which I haven’t been on; I can’t say how good they are, but they are cheaper, and they’re spread out. I think you do a day or two per week for a period of several weeks.
And I think that’s got to be really good because you’re going to have more time to consolidate this huge amount of information in your head. No disrespect to the face-to-face course. It was very good. I think the online courses could be even better and a lot more accessible. That was the course. Now, I did that in November twenty nineteen and I intended to do some revision and then take the exam probably in early.
In March, April 2020, global events got in the way of that, and all the exam centers were closed down. I couldn’t do that. Basically, I sort of forgot about it for a period of months. And then at the tail end of 2020, as things began to improve here in Australia at least, we’ve been very lucky here, exam centers reopened, and I thought, well, I really should get back and, you know, try and schedule the exam and do some revision and get on with it.
Exam Preparation
So I did. And starting in January of this year, I got my management agreement that I would spend one day a week working from home, revising, and that’s what I did. Given that I took the exam in the middle of May, that’s probably 18 full days of revision going through the material, and I needed it! Originally, I was going to take the exam, I think, in early April, but I realized at the end of March that I was not ready and I needed more time.
So I put the exam date back to the middle of May. And it was only after I’d done that that it was announced that the syllabus of the exam was changing quite significantly. That was a, you know, extra work then. And fortunately. They. They brought out the official guide to the new exam, and I realized that quite a lot of material to learn. I went through, and for example, there are eight domains in CISSP.
And for example, here’s domain number two, asset security. In the pink, I have highlighted all the new things that are in the 1st of May Edition syllabus that were not in the 2018 syllabus. I went through all of these things, and there are quite a few in almost every domain except the first one. There are significant changes. I had to do a lot of extra revision because the syllabus had changed, but nevertheless, it was doable.
To get regular updates from The Safety Artisan, Click Here. For more introductory lessons Start Here.
In this lesson, I will teach you how to demonstrate SFARP. I’ve been doing this on complex programs for 20+ years now, both in the UK and Australia. The concept of ‘reasonably practicable’ is much easier to apply than people think. I’ve watched a lot of programs over-complicate the process. We just don’t have to do that! I have some practical tips for you, not just theory…
The proper phrase, from the Australian WHS Act, is ‘how to eliminate or minimize risks so far as is reasonably practicable’. (The Act never uses the acronym SFARP or SFAIRP, but everyone else does.)
Apply those techniques, in the correct order, in practice.
These will allow you to perform most* SFARP demonstrations, confident that you know what you can and can’t do.
*A fully quantitative Cost-Benefit Analysis also requires you to understand and apply the concept of risk tolerability, which is another lesson.
Topics: How to Demonstrate SFARP
Introduction – Reasonably Practicable;
How to SFARP with:
Codes, Standards & Regulations; and
Controls, or groups of controls.
Some practical hints on good practice;
Examples; and
Source information.
Transcript: How to Demonstrate SFARP
Welcome to the safety artisan, I’m Simon and in this session, I’m going to be talking about SFARP – so far as is reasonably practicable.
This is a very misunderstood topic, but we’re going to be explaining how to demonstrate that risks have been eliminated or minimized so far as is reasonably practicable in accordance with Australian work, health, and safety law.
Topics
So, we’re going to be talking about how to demonstrate SFARP, in accordance with Australian WHS. The observant among you will notice that I don’t have an Aussie accent. I wasn’t born here, but I have worked in Australia on safety According to WHS for 10 years. So I have learned how to do it, and I think importantly, I’ve learned the differences from the way it’s done in the UK.
Because SFARP or ALARP is done in the UK. Although the legislation is different incidentally have a look at the lesson on Australian WHS for that. But that’s for another session.
Learning Objectives
So our learning objectives for this session at the end of this session, you should understand the SFARP concept and what it’s all about. You should understand the various techniques that are available to you and most importantly of all, you will be able to apply these techniques in the correct order because that’s important in the real world in practice. So those are the three general learning objectives.
Having learned these things, you will be able to perform most SFARP demonstrations confident that you know what you can do and what you can’t do. Perhaps more importantly, also what you should and shouldn’t do.
I say most SFARP demonstrations because to do a fully quantitative cost-benefit analysis, you will also need to understand the concept of risk tolerability and that’s another lesson. I will go through that in a practical example, but I’m not going to explain risk tolerability today.
Australian WHS
I’m going to go through what ‘reasonably practicable’ means in Australian WHS because that’s the key to the whole thing. Then we’re going to look at our various options for determining whether the risk is SFARP or not.
First, we’re going to look at codes of practice, standards, and regulations. In the second part, we’re going to look at how we assess controls or groups of controls to see whether we’ve done enough.
All the way through, I’m going to be giving you some practical hints and tips on good practice to use and bad practice to avoid – as part of that will cover some examples. I’ve got one particular example at the end, which you’ll see. Finally, some brief notes on source information and where you can get more information.
So that’s what we’re going to cover.
Introduction
Australian WHS legislation requires us, as I think I’ve said before, to eliminate or minimize risks so far as is reasonably practicable. That’s the origin of the acronym SFARP (you might see it written as SFAIRP), and the core concept of that is reasonably practicable. And this concept is in the WHS Act, it’s in the Regulations and it’s in the Codes of Practice.
My name’s Simon Di Nucci. I’m a practicing system safety engineer, and I have been, for the last 25 years; I’ve worked in all kinds of domains, aircraft, ships, submarines, sensors, and command and control systems, and some work on rail air traffic management systems, and lots of software safety. So, I’ve done a lot of different things!